Deploying a TensorFlow Model with TensorFlow Serving and Docker: A Step-by-Step Guide using Universal Sentence Encoder (USE)

TensorFlow Serving is a powerful tool for deploying machine learning models in a production environment. It allows for easy scaling and management of models, as well as the ability to serve multiple models at once. One of the most convenient ways to use TensorFlow Serving is through the use of Docker containers. In this article, we will go through the process of deploying a TensorFlow model using TensorFlow Serving in a Docker container, using the Universal Sentence Encoder as an example.
The first step in deploying a TensorFlow model using TensorFlow Serving in a Docker container is to export the model. This can be done using the TensorFlow SavedModel format. The Universal Sentence Encoder, for example, can be exported using the following code snippet:
import tensorflow as tf
# Load the Universal Sentence Encoder model
model = tf.saved_model.load("path/to/model")
# Create a signature definition for the model
signature_def = tf.compat.v1.saved_model.signature_def_utils.predict_signature_def(
inputs={"input": model.inputs[0]}, outputs={"output": model.outputs[0]})
# Export the model
builder = tf.saved_model.builder.SavedModelBuilder("path/to/export")
builder.add_meta_graph_and_variables(
sess=tf.compat.v1.Session(),
tags=[tf.saved_model.tag_constants.SERVING],
signature_def_map={
tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY:
signature_def
})
builder.save()Once the model has been exported, it can be used to create a Docker image for TensorFlow Serving. To do this, we will use the TensorFlow Serving base image, and add our exported model to it. The following code snippet shows an example of how to create a Dockerfile for the Universal Sentence Encoder:
FROM tensorflow/serving
COPY path/to/export /models/universal_sentence_encoder
ENV MODEL_NAME universal_sentence_encoder
ENTRYPOINT ["/usr/bin/tf_serving_entrypoint.sh"]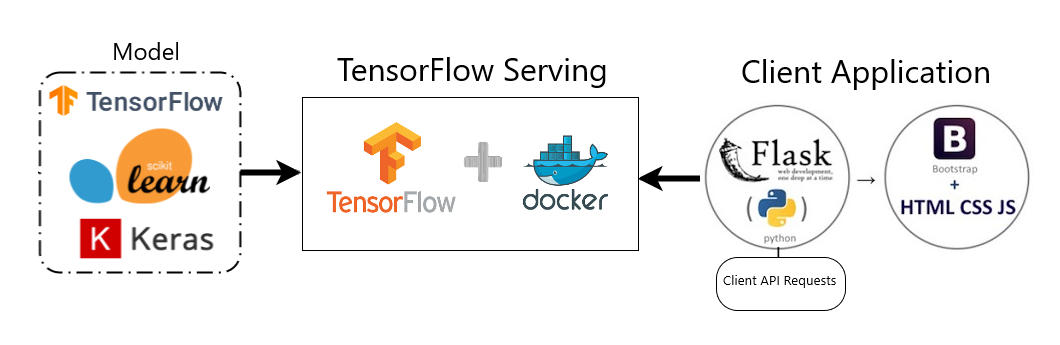
Now, we can use the Dockerfile to build the image. This can be done using the following command:
docker build -t tensorflow_serving_universal_sentence_encoder .Once the image has been built, we can run it as a container. To do this, we will use the following command:
docker run -p 8501:8501 --name tf_serving_universal_sentence_encoder -t tensorflow_serving_universal_sentence_encoderThis will start the TensorFlow Serving container, and make it available at port 8501. We can now use the Universal Sentence Encoder model to encode sentences by sending a POST request to the following URL:
http://localhost:8501/v1/models/universal_sentence_encoder:predictThe request body should be in the following format:
{
"instances": [
"Sentence 1",
"Sentence 2",
"Sentence 3"
]
}The response will be a JSON object containing the encoded sentences.
In conclusion, deploying a TensorFlow model using TensorFlow Serving in a Docker container is a convenient and efficient way to serve machine learning models in a production environment. It allows for easy scaling and management of models, as well as the ability to serve multiple models at once. By following the steps outlined in this article, you can easily deploy the Universal Sentence Encoder, or any other TensorFlow model, using TensorFlow Serving in a Docker container.
For similar kinds of content, you can follow me on GitHub, Twitter and LinkedIn.
